Notions abordées dans les démonstrations METISS
variabilite.php
La variabilité des signaux audios 
 |
Les humains sont capables d'une certaine souplesse quand ils associent
leurs perceptions à un objet: un chat est un chat, qu'il soit
noir ou tigré, siamois ou persan, dans un jardin ou sur une photo.
Pour l'ordinateur, c'est plus difficile: il ne fonctionne
que dans les situations pour lesquelles il a été programmé.
Il n'a pas de capacité propre à appréhender
le monde qui l'entoure dans toute sa généralité.
Il faut donc concevoir des méthodes qui lui permettent de fonctionner
dans des contextes très variés. Comme pour les chats, les
sons présentent une grande diversité, que l'on désigne
sous le terme de variabilité. En voici quelques illustrations
: |
 |
Une même personne ne parle pas tout le temps de la même
façon
Par exemple, on ne parle pas pareil suivant que l'on est calme, stressé,
enrhumé, entouré de bruit, etc ... En jargon scientifique,
les variations de la voix d'une même personne sont appelées
variabilité intra-locuteur. Ce phénomène existe également
pour les notes produites par un instrument de musique, selon les nuances
et l'interprétation.
|
 |
 |
Nous avons tous des timbres de voix différents
Des personnes différentes parlent différemment selon leur
âge, leur accent, la forme de leur conduit vocal,... C'est la
variabilité inter-locuteur. De même, différents instruments
ont des timbres différents, même s'ils jouent la même
mélodie.
|
 |
|
Les microphones déforment les sons
Quand un son passe à travers un micro (par ex emple, un combiné
téléphonique), il subit des déformations. C'est aussi le
cas quand il est transmis sur les ondes, sur un réseau, sur Internet,
... Ce type de variabilité est appelée distorsion de canal . Il
concerne aussi bien la voix que tous les autres types de sons lorsqu'ils sont
enregistrés ou transmis.
|
 |
|
Nous vivons entourés de bruit
Le bruit environnant fait partie de la vie courante. Par exemple, quand on
téléphone de la gare au moment où le train arrive, le bruit
se mélange à la voix ! Cette variabilité due au bruit environnant
est difficilement prévisible et elle nécessite des traitements
spécifiques pour être neutralisée.
|
 |
analyse_parole.php
Analyse du signal de parole
Le signal de parole est tout d'abord divisé en petites trames de 20ms
correspondant à une durée où le signal de parole ne varie
pas beaucoup.
La première étape d'analyse segmente l'enregistrement pour ne
garder que les zones ou une activité de parole est détectée.
Pour cela on détecte les zones qui contiennent relativement le plus d'énergie.
On extrait ensuite du signal segmenté des caractéristiques propres
à la voix par des ransformations mathématiques. Les caractéristiques
extraites sont en relation avec le contenu fréquentiel de la parole,
la forme du conduit vocal, l'intonation ou encore la prosodie. Pour chaque trame
de parole on extrait un vecteur de 20 à 30 caractéristiques qui
sont les coefficients "cepstraux", leurs dérivés et
l'énergie du signal.
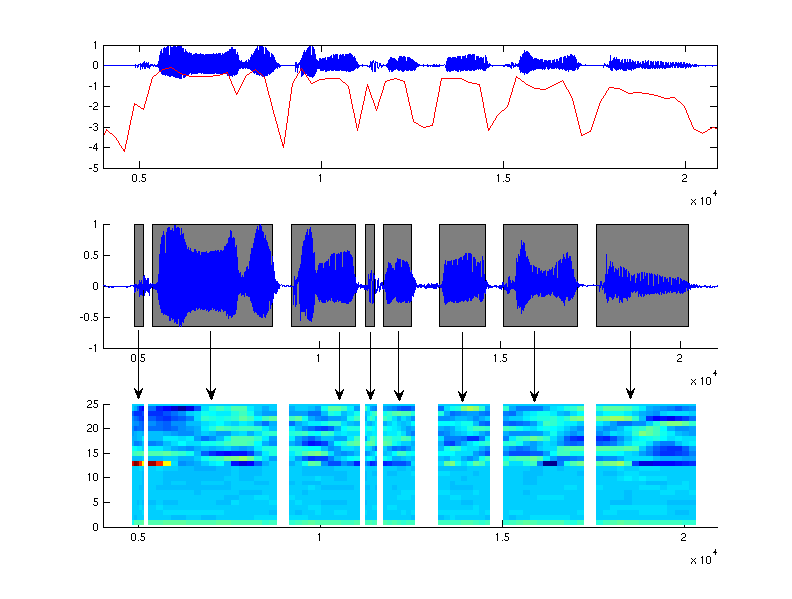 Figure: Les étapes de l'analyse d'un signal de parole.
Figure: Les étapes de l'analyse d'un signal de parole.
Haut: Signal enregistré.
Milieu: segmentation par détection des zones les plus énergétiques.
Bas: Paramétrisation du signal en coefficients cepstraux.
|
test_authentification.php
Procédure d'authentification
Disposant des modèles statistiques de chaque voix, on regarde pour chaque
trame la ressemblance des caractéristiques avec les modèles.
On distingue deux types d'authentification
- la vérification: on ne présente qu'une voix à authentifier.
Dans ce cas là, le seuil d'authentification joue un rôle très
important et va définir la sécurité du système. La sécurité
est définie par les taux erreurs que commet le système en terme
de rejet de bon locuteur (faux rejet) et d'acceptation de mauvais locuteur.
- l'identification: on cherche à authentifier une voix parmi N>1.
Pour cela, on calcule les vraisemblances du test avec tous les modèles
connus du système. Le locuteur qui a le modèle le plus vraisemblable
est identifié. Etant donné qu'un des modèles obtient toujours
le meilleur score, on fixe comme pour la vérification un seuil minimal
de vraisemblance pour authentifier le locuteur.
modeles_probabilistes.php
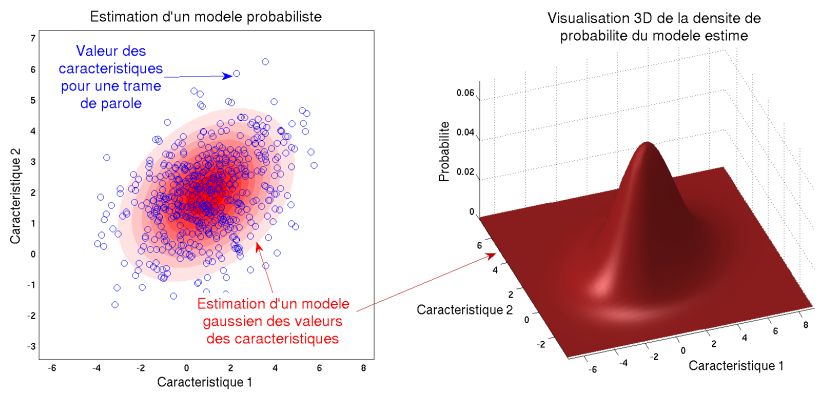
Modèles probabilistes
On crée pour chaque voix un modèle statistique des caractéristiques,
c'est-à-dire que l'on modélise la répartition des informations
(moyenne, étalement) plutôt que des valeurs précises de
coefficients. On utilise des "modèles à mélange de
gausiennes", appelés GMM, qui permettent de modéliser des
formes complexes de distribution des caractéristiques. Les modèles
couramment utilisés sont constitués de plusieurs centaines de
gaussiennes.
Utilisation d'un modèle du monde
En raison de la variabilité des enregistrements et des voix, un seul
enregistrement de courte durée ne permet pas de créer un modèle
robuste pour reconnaître la voix d'une personne. Pour pallier ce problème
une solution consiste à créer les modèles de voix à
partir d'un modèle générique plutôt que de toute
pièce. Ce modèle générique est appelé "modèle
du monde" et est entraîné sur une grande variabilité
de parole (nombreuses personnes, contenu varié, différents types
de microphones, d'ambiances acoustiques, ...). Chaque modèle est adapté
de ce modèle pour reflèter au mieux les caractéristiques
propres à chaque voix.
Modèle gaussien
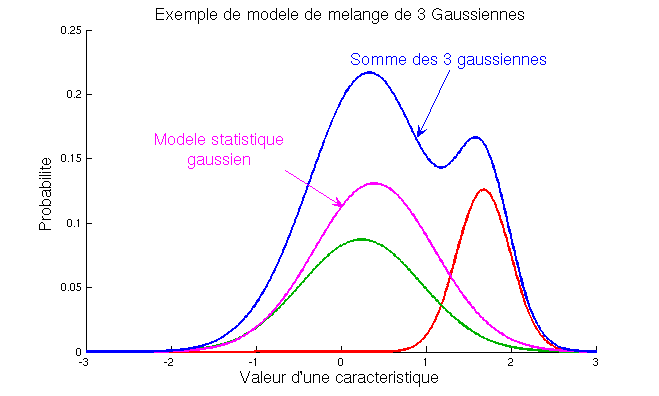
Modèle de mélange de gaussiennes
signaux_temporel.php
Représentation d'un signal sonore
A faire
detecteur_activite.php
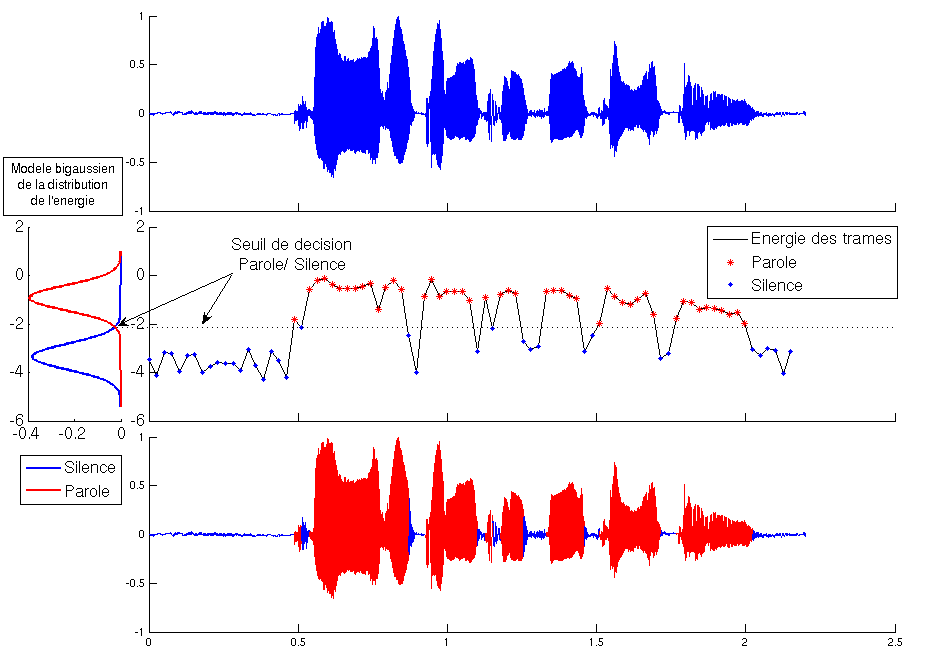
Détection d'activité de parole
Lorsque l'on dispose d'un enregistrement de parole, la premičre phase d'analyse consiste ŕ séparer les
zones de silence des zones ou il y a vraiment de la parole. Pour effectuer cette séparation, on se base l'énergie du signal.
Ainsi, on ne conserve que les parties oů l'énergie du signal est supérieure ŕ un certain seuil.
La principale difficulté réside alors dans le choix d'un seuil approprié ŕ chaque signal.
Le seuil est obtenu en regardant la distribution statistique de l'énergie du signal.
On segmente tout d'abord le signal en trames de 20ms (+ explication dans notions générales).
Ce choix de longueur de trames pour l'analyse du signal de parole est obtenue de maničre empirique et repose sur
l'hypothčse que la parole varie peu en 20ms. En calculant l'énergie de chacune des trames,
prise_de_son.php
La prise de son
A faire
tfct_signaux.php
Spectre et décomposition temps fréquence
Analogie avec une partition musicale
