| Présentation | - | Démonstrations | - | Difficultés | - | Thématiques | - | Historique | - | Aujourd'hui | - | Et demain ... |
| Retour à l'accueil |

|
|
Les signaux sonores que nous produisons et que nous percevons autour de nous forment un environnement sonore dans lequel nous avons appris à distinguer les sons, et à les associer à des objets (Vrrroummm!), à des situations (Paf!), à des mots (Bonjour), à de la musique ou à d’autres concepts. Pour la machine, c’est une autre histoire : elle n’a pas de connaissance globale du monde. Pour interpréter un son, elle ne peut pas s’appuyer sur une expérience acquise dans des situations très variées. Au même mot dans différentes phrases, dans une chanson ou avec un fort bruit de fond correspondent en fait des sons très différents que seul l'homme sait interpréter comme ayant le même sens. Analyser, décomposer, comparer et reconnaître les sons par des traitements automatiques, tel est l'enjeu des recherches en Traitement des Informations et des Signaux Sonores. Dans ce domaine, le métier de chercheur consiste à développer les connaissances, les algorithmes et les méthodes qui permettent de manipuler l’information contenue dans les sons. Pour cela, on construit des modèles qui s'appuient sur des connaissances issues de nombreux autres domaines : la linguistique, la musique, l'acoustique, les mathématiques, les statistiques, l'intelligence artificielle, etc... Et naturellement, on utilise l'informatique ! C'est la mise en commun des connaissances issues de toutes ces disciplines, aidée par le progrès constant de la puissance de calcul des ordinateurs, qui permet d’être toujours plus ambitieux. Grâce à un va et vient permanent entre la théorie et l’expérience, on affine progressivement la compréhension des problèmes à résoudre en enrichissant les connaissances, en concevant de nouveaux modèles et en développant de nouveaux outils. Le chercheur formalise des méthodes, propose des solutions puis les confronte à l'expérience et mesure les progrès accomplis. Il identifie aussi les difficultés qui restent à résoudre pour pouvoir aller plus loin. Du point de vue des applications, cela fait longtemps que, dans les films et les livres de science-fiction, on voit des personnages parler à des machines :
Par contre, dans notre vie de tous les jours, ces technologies n'ont pas atteint un tel stade de développement. Mais d’autres, auxquelles on n’avait pas forcément pensé, voient le jour grâce aux résultats des recherches menées dans les laboratoires : serveurs vocaux, dictée sur ordinateur, renseignements téléphoniques sans opérateur, karaoké automatique, musique compressée au format mp3, spatialisation du son (effet surround), etc... Ces applications commencent à peupler notre quotidien, grâce aux progrès scientifiques et aux avancées technologiques de ces dernières décennies. Demain, grâce aux recherches en cours, de nouvelles connaissances et de nouveaux modèles permettront à d’autres applications de voir le jour. Actuellement, on travaille par exemple dans le domaine du multimédia, sur les "moteurs de recherche sonore" pour retrouver un reportage particulier dans des archives radiophoniques, un refrain qu’on chantonne dans une base de données musicale sur Internet, les temps forts dans les commentaires des matches de foot, ... D'autres domaines d'application tirent aussi parti des travaux de recherche menés aujourd'hui dans les laboratoires :
Plus ces nouveaux usages vont se répandre, plus les chercheurs vont être confrontés à de nouvelles problématiques scientifiques. Ils devront répondre en étendant encore davantage le champ des connaissances et en proposant des solutions toujours plus innovantes. |
Nous vous proposons de rentrer plus dans le détail de trois des thématiques de recherche de l'équipe METISS :
Vous pouvez également en savoir plus sur la recherche dans le domaine du traitement du son en lisant la suite du texte. Vous y trouverez une présentation des principales difficultés sur lesquelles se penchent les chercheurs un historique des grandes découvertes, un point sur les thèmes de recherches actuels. Et demain...
| Difficultés | - | Thématiques | - | Historique | - | Aujourd'hui | - | Et demain ... |
 |
Les humains sont capables d’une certaine souplesse quand ils associent leurs perceptions à un objet: un chat est un chat, qu’il soit noir ou tigré, siamois ou persan, dans un jardin ou sur une photo. Pour l’ordinateur, c’est plus difficile: il ne fonctionne que dans les situations pour lesquelles il a été programmé. Il n’a pas de capacité propre à appréhender le monde qui l'entoure dans toute sa généralité. Il faut donc concevoir des méthodes qui lui permettent de fonctionner dans des contextes très variés. Comme pour les chats, les sons présentent une grande diversité, que l'on désigne sous le terme de variabilité. En voici quelques illustrations : |
 |
Une même personne ne parle pas tout le temps de la même façonPar exemple, on ne parle pas pareil suivant que l'on est calme, stressé, enrhumé, entouré de bruit, etc ... En jargon scientifique, les variations de la voix d’une même personne sont appelées variabilité intra-locuteur. Ce phénomène existe également pour les notes produites par un instrument de musique, selon les nuances et l'interprétation. |
 |
 |
Nous avons tous des timbres de voix différentsDes personnes différentes parlent différemment selon leur âge, leur accent, la forme de leur conduit vocal, … C'est la variabilité inter-locuteur. De même, différents instruments ont des timbres différents, même s'ils jouent la même mélodie. |
 |
|
Les microphones déforment les sonsQuand un son passe à travers un micro (par ex emple, un combiné téléphonique), il subit des déformations. C'est aussi le cas quand il est transmis sur les ondes, sur un réseau, sur Internet, ... Ce type de variabilité est appelée distorsion de canal . Il concerne aussi bien la voix que tous les autres types de sons lorsqu'ils sont enregistrés ou transmis. |
 |
|
Nous vivons entourés de bruitLe bruit environnant fait partie de la vie courante. Par exemple, quand on téléphone de la gare au moment où le train arrive, le bruit se mélange à la voix ! Cette variabilité due au bruit environnant est difficilement prévisible et elle nécessite des traitements spécifiques pour être neutralisée. |
 |
|
La taille du vocabulaire varie selon les situationsQuand on veut reconnaître un numéro de téléphone, on a juste besoin de savoir distinguer 10 chiffres. Mais quand on dicte une lettre, le vocabulaire utile peut être composé de plus de 60000 mots; cela accroît les possibilités d'ambiguïté. C'est la complexité due au vocabulaire. |
 |
|
Les sons parviennent mélangés à nos oreillesL' être humain est capable de distinguer les différentes sources sonores qui constituent son environnement acoustique (par exemple, une personne qui parle sur un fond musical). Reproduire cette capacité de manière automatique nécessite de mettre en oeuvre des techniques de séparation de source pour isoler les différents composants d'un mélange sonore.
|
 |
Chacune de ces difficultés constitue un sujet de recherche à
part entière:
|
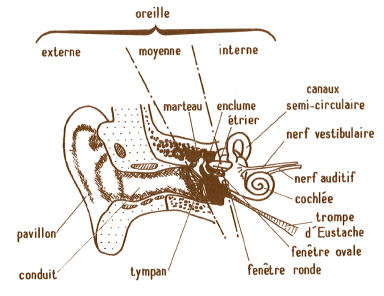
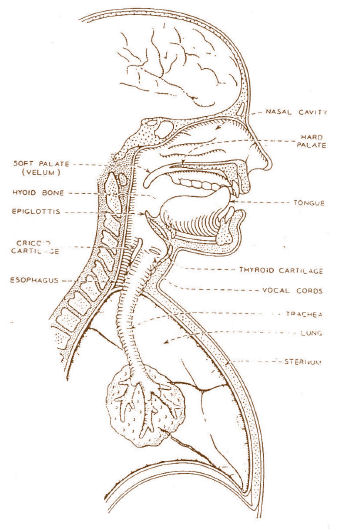
PréambuleL'être humain est équipé d'un appareil vocal pour produire des sons et d 'un système auditif pour les percevoir. Depuis plusieurs siècles, il a tenté de reproduire artificiellement ces mécanismes. Mais les 50 dernières années ont été particulièrement riches en progrès, grâce à l'accroissement de la puissance de calcul des ordinateurs et à l'utilisation de modèles de plus en plus élaborés de la parole et du son.
|
 |
 Alors
que les chinois connaissent le boulier depuis 300 av. JC, Pascal propose en
1642 une machine à calculer mécanique, perfectionnée en
1671 par Leibniz. Ce sont les ancêtres de l'ordinateur.
Alors
que les chinois connaissent le boulier depuis 300 av. JC, Pascal propose en
1642 une machine à calculer mécanique, perfectionnée en
1671 par Leibniz. Ce sont les ancêtres de l'ordinateur.
En 1791, le baron Von Kempelen, alors employé à la cour de Vienne, imagine et fabrique une "machine parlante" qui reproduit les fonctions du conduit vocal à l'aide d'un système en bois, cuir et ivoire. C'est le premier synthétiseur vocal de l'histoire.
A l'époque, il s'agit plus de curiosités scientifiques que d'applications utilisables dans la vie de tous les jours.

1896: Conception du premier synthétiseur de musique électro-acoustique: le dynamophone par Taddheus Cahill.
1939: VODER d'Homer Dudley (Bell Labs), synthétiseur de parole manuel basé sur les composants électroniques connus à l'époque .
1952: reconnaissance automatique de 10 chiffres isolés prononcés par un même locuteur aux Bell Labs, USA.
1961-1963 : plusieurs laboratoires ja ponais construisent du matériel électronique dédié pour des tâches simples de reconnaissance de la parole.
Ces différents systèmes de reconnaissance et de synthèse de la parole et du son sont sommaires et fonctionnent avec des composants électroniques dédiés (matériel analogique), comme par exemple les "bancs de filtres".

1945 : construction de l'ENIAC d'IBM, premier calculateur numérique géant de l'histoire . Il pèse plus de 30 tonnes et occupe toute une pièce de l'université de Pennsylvanie (USA). Il contient 19000 lampes à vide et 1500 relais.
1960 - 1965 : Invention du circuit intégré. Au lieu de souder des composants électroniques digitaux sur des circuits imprimés, on les grave directement sur une couche de silicium, appelée puce. Au début, les ordinateurs sont encore de grosses armoires, mais ils deviennent progressivement moins encombrants et moins chers. Pour tester des théories, il devient possible d'utiliser des simulations numériques. L'utilisation des mini-ordinateurs, tels que l'IBM 360 et le NEC PDP-8, se généralise
1970 : le premier microprocesseur Intel, le 4004 (4 bits, 108 kHz, 2300 transistors), inaugure l'ère des microprocesseurs à "intégration à grande échelle" (LSI), c'est à dire intégrant 500 transistors ou plus sur la même puce . Cela permet de réduire encore la taille et le prix des ordinateurs : on peut maintenant en avoir un sur son bureau.
Parallè!lement, dans les années 1970, les convertisseurs analogique/numérique et numérique/analogique se développent et permettent de transmettre et de stocker les signaux échantillonnés au format PCM, ouvrant la voie au traitement numérique du son.
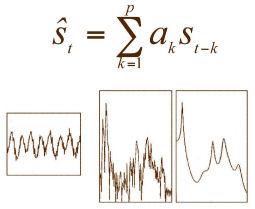
1970 : la méthode de codage de parole par prédiction linéaire (Linear Prediction Coding, ou LPC) est développée par John Makhoul aux USA (Bell Labs, 1971) et Fumitada Itakura au Japon (NEC, 1975).
Il s'agit d'une méthode d'analyse de la parole qui permet de décrire économiquement le contenu d'un son. La prédiction linéaire aura une influence majeure dans tous les domaines du traitement des signaux sonores, de la compression (norme GSM) à la reconnaissance de parole en passant par la synthèse sonore.
1978 : T exas Instruments fabrique et commercialise le jouet "Dictée Magique", qui incorpore une puce de compression de parole basée sur la LPC.
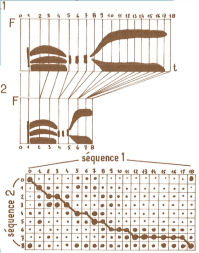
1968 : en Russie, Vintsyuk propose de comparer des séquences de longueurs différentes par la technique de programmation dynamique (algorithme de Viterbi).
1978 : au Japon, Sakoe et Chiba appliquent cette méthode à la reconnaissance de la parole, pour prendre en compte les différences dans la vitesse d'élocution d'un même phonème ou d'un même mot.
La technique de programmation dynamique permet de réaliser en laboratoire des systèmes de reconnaissance de quelques mots en mode dépendant du locuteur . L'algorithme de Viterbi reste au coeur des systèmes de reconnaissance actuels, dans une forme plus élaborée.
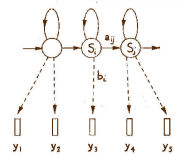
1976 : les travaux de Baker et Jelinek (IBM, USA) consistent à appliquer les Modèles de Markov Cachés (Hidden Markov Models, HMMs) développés par Baum en 1972, à la reconnaissance de la parole. Ces modèles permettent de prendre en compte les variations possibles du contenu sonore d'un phonème ou d'un mot donné. Ils débouchent sur des systèmes de reconnaissance de mots isolés relativement robustes aux variations de prononciation par un même locuteur.
1979 : aux laboratoires AT&T, début des recherches sur les systèmes de reconnaissance indépendants du locuteur.
1981-1989 : travaux sur la reconnaissance de la parole continue (Rabiner , Bell Labs, USA). L'application des HMMs à la reconnaissance de la parole est de mieux en mieux maîtrisée et permet la modélisation acoustique et lexicale.
1989 : En exploitant les imperfections du système auditif humain (notamment l'effet de masque fréquentiel), le Fraunhofer Institute invente une nouvelle norme de compression du son : le MP3 (pour MPEG 1 - La y er 3). L 'information présente dans le son est compressée en supprimant les fréquences que l'oreille humaine ne peux pas entendre du fait qu'elles sont masquées par des fréquences voisines plus intenses présentes dans ce même son.
1997 : Tomislav Uzelac (USA) programme AMP MP3 Player, l'ancêtre de WinAmp.
1999 : apparition des premiers baladeurs MP3.
1990 : les recherches en reconnaissance de parole dite "à grand vocabulaire" arrivent à une certaine maturité.
1995 : des produits de dictée vocale sont mis en vente pour le grand public : Drag on Dictate , Kurzweil Voice , IBM Voice Type Dictation, etc ... Au départ, ils ne fonctionnent que dans un environnement calme, pour un seul utilisateur et en mode "mots isolés" (32 000 mots). Au fil des ans, la taille du vocabulaire reconnu augmente, et la dictée peut s'opérer en parole continue (enchaînement des mots).
A cette même période, on commence à en visager la mise en place de serveurs vocaux automatiques délivrant des informations téléphoniques pour les entreprises (chez AT&T (USA), ATR (Ja pon), au CNET (France), etc ...).
Puis, l'accroissement de la puissance des ordinateurs et les progrès accomplis dans les laboratoires permettent de déployer des applications plus complexes et plus robustes.

Les processeurs récents tournent entre 1 et 3 GHz et les ordinateurs grand public peuvent être dotés d'1 Go de mémoire vive. Les recherches dans le domaine du traitement de la parole et du son continuent pour apporter des solutions à des problèmes toujours plus complexes dans des ap plications toujours plus ambitieuses :
Pour faciliter l'utilisation des systèmes vocaux, il est important que le dialogue entre l'homme et la machine s'effectue dans un mode le plus naturel possible. Ceci nécessite de pouvoir traiter des énoncés de parole spontanée et de comprendre ce que souhaite un utilisateur qui peut formuler une même requête de différentes façons.
Ces recherches allient la reconnaissance de la parole au traitement du langage naturel pour concevoir des systèmes de dialogue plus performants et plus conviviaux.
 Les recherches actuelles en reconnaissance de la parole visent à
modéliser des vocabulaires de plusieurs centaines de milliers de
mots (par exemple, l'annuaire d'une grande ville).
Les recherches actuelles en reconnaissance de la parole visent à
modéliser des vocabulaires de plusieurs centaines de milliers de
mots (par exemple, l'annuaire d'une grande ville).
Déjà, IBM ViaVoice et Dragon Naturally Speaking, commercialisés par SpeechWorks, peuvent reconnaître 150000 mots en parole naturelle prononcée à 140-160 mots/minute, avec un taux de reconnaissance annoncé de 99 % (ils nécessitent au minimum un Pentium III à 500 MHz avec 256 Mo de RAM, mais il existe aussi une version pour ordinateur de poche Palm Pilot).
On cherche aujourd'hui à aller encore plus loin, par exemple à traiter des vocabulaires de plusieurs millions de mots ce qui pose des problèmes de complexité de calcul et d'ambiguïté acoustique.
Pouvoir utiliser un système de reconnaissance vocale sur son téléphone mobile nécessite de rendre les algorithmes plus robustes aux perturbations sonores extérieures.
D'autre part, on essaye de faire des appareils portables toujours plus petits (pensez à la taille d'un baladeur MP3 par rapport à celui d'un vieux magnétophone).
La robustesse au bruit, la miniaturisation et l'adaptabilité à différents réseaux de communication constituent des enjeux majeurs de recherche en traitement de la parole et du son.
Les archives nationales de plusieurs pays sont en cours de numérisation. Ainsi l'INA (Institut National de l'Audiovisuel) dispose de plus d'1.5 m i l l ion d'heures de programmes TV et radio qui seront à terme accessible par internet. Et chaque jour, des milliers d'heures de flux de programmes transitent sur les réseaux de diffusion. Dès le milieu des années 1990, les recherches progressent vers la transcription de données sonores provenant de la TV ou de la radio. Ce domaine d'application suscite de nouveaux travaux : séparation entre la parole la musique, reconnaissance du locuteur, détection de jingles, de morceaux de musique, de type de prise de son, etc ... Plus généralement, cette branche du domaine évolue vers l'indexation sonore, c'est-à-dire la caractérisation du contenu d'enregistrements sonores pour la production, la navigation et la recherche d'information dans les documents audio.

| Retour à l'accueil |
Illustrations: Joub et Nicoby 2005 - Site réalisé par l'équipe METISS